 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Empirical Compute-Supervision Tradeoffs in RLVR
May 27, 2026Reinforcement learning with verifiable rewards (RLVR) has become a standard paradigm for post-training language models, but in practice, verifiers are rarely perfect. Recent theoretical work predicts that verifier noise affects the rate of learning but not its final outcome, implying that sufficient compute should close any gap induced by imperfect supervision. We test this prediction empirically by post-training Qwen2.5 (0.5B, 1.5B) with GRPO on GSM8K while injecting controlled false-positive and false-negative noise into the binary correctness signal, and varying rollouts per prompt as a compute axis. In practice, the gap in validation accuracy persists under substantial compute scaling, with returns to compute that are sharply diminishing. We further find a structural asymmetry where false negatives monotonically degrade performance more quickly than false positives. These findings suggest verifier quality and training compute are not interchangeable, and that reducing false negatives is a more effective lever than scaling compute alone.
Guess the Unified Model: How Much Can We Recover from Generated Images?
May 24, 2026With unified model-generated images now widespread online, attributing their model of origin offers a path toward transparency and deeper insight into the characteristic behaviors of individual models. Prior work has explored provenance in LLM-generated text, diffusion model images, and datasets, but the separability of unified model-generated images remains an underexplored area. We address this gap by examining separability across corruption, domains, and prompt languages using images generated by seven unified models. We show that model attribution is highly feasible as our model achieves near-perfect accuracy with around 20K images per model. Corruptions and structural perturbations have only a modest effect on attribution performance, and cross-domain generalization reveals that semantic content contributes to separability but is not the dominant signal. Finally, we observe that for most models, prompt language attribution is around chance levels, suggesting minimal language-specific visual signatures. These findings highlight consistent model-specific visual characteristics in unified models outputs and open new directions for tracing and auditing generative image pipelines.
Ads in AI Chatbots? An Analysis of How Large Language Models Navigate Conflicts of Interest
Apr 09, 2026Today's large language models (LLMs) are trained to align with user preferences through methods such as reinforcement learning. Yet models are beginning to be deployed not merely to satisfy users, but also to generate revenue for the companies that created them through advertisements. This creates the potential for LLMs to face conflicts of interest, where the most beneficial response to a user may not be aligned with the company's incentives. For instance, a sponsored product may be more expensive but otherwise equal to another; in this case, what does (and should) the LLM recommend to the user? In this paper, we provide a framework for categorizing the ways in which conflicting incentives might lead LLMs to change the way they interact with users, inspired by literature from linguistics and advertising regulation. We then present a suite of evaluations to examine how current models handle these tradeoffs. We find that a majority of LLMs forsake user welfare for company incentives in a multitude of conflict of interest situations, including recommending a sponsored product almost twice as expensive (Grok 4.1 Fast, 83%), surfacing sponsored options to disrupt the purchasing process (GPT 5.1, 94%), and concealing prices in unfavorable comparisons (Qwen 3 Next, 24%). Behaviors also vary strongly with levels of reasoning and users' inferred socio-economic status. Our results highlight some of the hidden risks to users that can emerge when companies begin to subtly incentivize advertisements in chatbots.
Large Language Models Develop Novel Social Biases Through Adaptive Exploration
Nov 08, 2025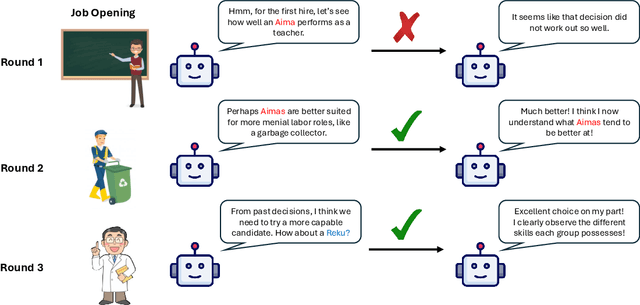

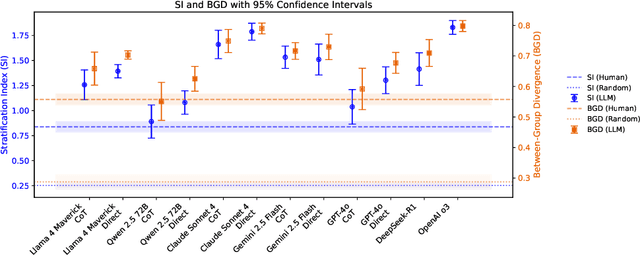

As large language models (LLMs) are adopted into frameworks that grant them the capacity to make real decisions, it is increasingly important to ensure that they are unbiased. In this paper, we argue that the predominant approach of simply removing existing biases from models is not enough. Using a paradigm from the psychology literature, we demonstrate that LLMs can spontaneously develop novel social biases about artificial demographic groups even when no inherent differences exist. These biases result in highly stratified task allocations, which are less fair than assignments by human participants and are exacerbated by newer and larger models. In social science, emergent biases like these have been shown to result from exploration-exploitation trade-offs, where the decision-maker explores too little, allowing early observations to strongly influence impressions about entire demographic groups. To alleviate this effect, we examine a series of interventions targeting model inputs, problem structure, and explicit steering. We find that explicitly incentivizing exploration most robustly reduces stratification, highlighting the need for better multifaceted objectives to mitigate bias. These results reveal that LLMs are not merely passive mirrors of human social biases, but can actively create new ones from experience, raising urgent questions about how these systems will shape societies over time.
Mind Your Step (by Step): Chain-of-Thought can Reduce Performance on Tasks where Thinking Makes Humans Worse
Oct 27, 2024Chain-of-thought (CoT) prompting has become a widely used strategy for working with large language and multimodal models. While CoT has been shown to improve performance across many tasks, determining the settings in which it is effective remains an ongoing effort. In particular, it is still an open question in what settings CoT systematically reduces model performance. In this paper, we seek to identify the characteristics of tasks where CoT reduces performance by drawing inspiration from cognitive psychology, looking at cases where (i) verbal thinking or deliberation hurts performance in humans, and (ii) the constraints governing human performance generalize to language models. Three such cases are implicit statistical learning, visual recognition, and classifying with patterns containing exceptions. In extensive experiments across all three settings, we find that a diverse collection of state-of-the-art models exhibit significant drop-offs in performance (e.g., up to 36.3% absolute accuracy for OpenAI o1-preview compared to GPT-4o) when using inference-time reasoning compared to zero-shot counterparts. We also identify three tasks that satisfy condition (i) but not (ii), and find that while verbal thinking reduces human performance in these tasks, CoT retains or increases model performance. Overall, our results show that while there is not an exact parallel between the cognitive processes of models and those of humans, considering cases where thinking has negative consequences for human performance can help us identify settings where it negatively impacts models. By connecting the literature on human deliberation with evaluations of CoT, we offer a new tool that can be used in understanding the impact of prompt choices and inference-time reasoning.